
GIGO – Garbage In, Garbage Out.
- If your raw data is flawed there is little hope for meaningful analysis.
- If your data is questionable then your analysts will be forced to spend unplanned resources tracking down and then correcting or working around bad data
- If your data is poorly organized then finding the information required to produce the necessary reports becomes an exercise in frustration
- If your data isn’t normalized – i.e. in the same format, units, geospatial reference models, etc – then significant resources will be required to normalize it before any meaningful analysis can be performed
Similar to ediscovery projects and digital forensics investigations, investing time up front to collect, organize, normalize and validate your data will save significant time later, help the project stay on schedule, and produce more accurate results.
Here is a diagram of a data collection process we used at a recent event:
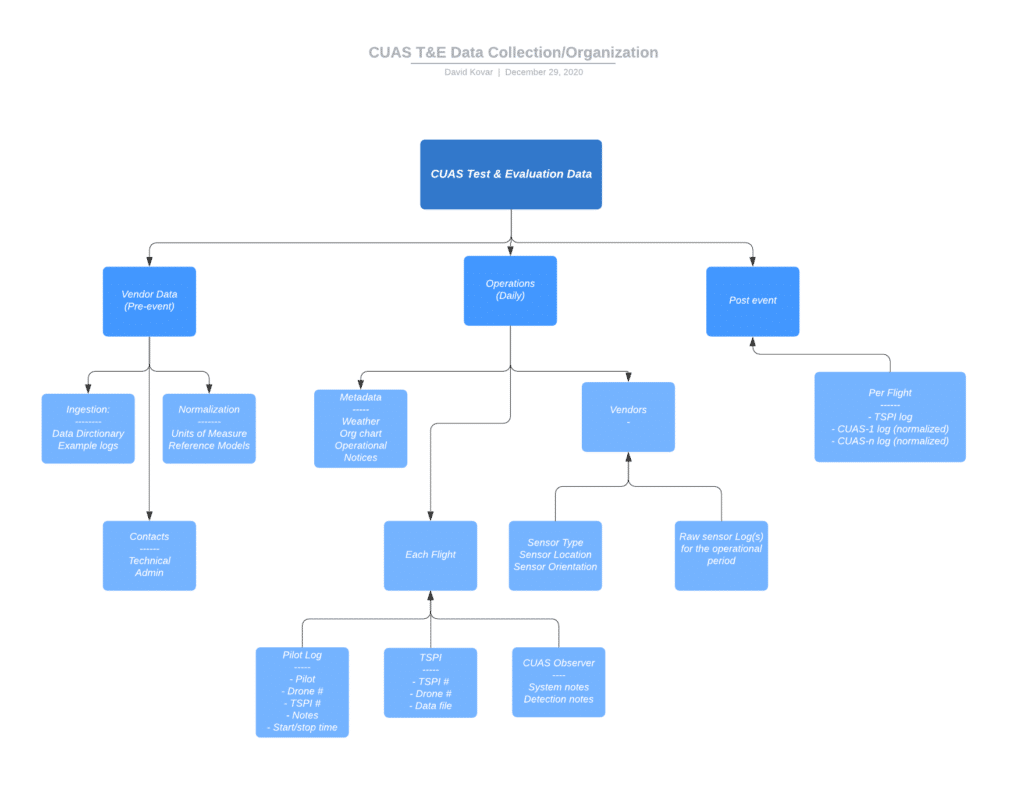
Collection
This is the most critical step. If you don’t collect the data during the exercise you’ll likely never get it. You cannot do the flights again, you cannot mitigate the drone that is now in the river, you cannot get logs from the vendor that wiped their systems.
And collect everything. You may not need it, but if you want it later, best to have it now.
Get:
- CUAS logs
- CUAS API data, likely preserved in the system of record’s databases
- UAV logs from both the ground control station and the UAV
- TSPI data, real time and post flight
- Observer logs from observers with the pilots, CUAS operators, and command room
- Collector logs – The team doing the collection should be creating an audit trail of everything they are doing
I cannot stress this enough. If you don’t do anything else, get as much data as you possibly can as soon as you can and preserve it in multiple locations.
Organization
We have all found ourselves spending hours sifting through file folders, multiple computers, different shared file systems, all to find the information we know exists but don’t remember where we put it. You just collected everything so take a few more minutes to apply some simple organization to it.
- Where – Where are you going to keep the master set? You can always duplicate it for sharing, work, or archive purposes but you need to know where all of the original data is, and know that it will not get modified. (You can add to it, just do not remove anything.) Some form of cloud based storage is probably best, but your organization’s policies will likely determine this for you.
- File naming convention – If you name all of the files in a standard way up front, finding what you need later will be much easier.
- I almost always start with <year>-<mon>-<day> in that order. If all of the files somehow end up merged together, a simple sort puts everything in chronological order
- For CUAS data you might add <vendor>-<sensor>. Now it is easy to find all of the files associated with a particular vendor and sensor
- If you know what flight a file is associated with, include <flight id>
- You will end up with something like:2021-01-21-URSA-radar-J203A simple file search will locate all of URSA’s files, or all files associated with flight J203, or all files for a particular day. No tags, no indexes no databases required.
- Folder structure – Similar to file naming conventions, setting up a logical folder structure (and possibly providing a tree diagram to introduce people to it) can save a lot of aggravation
We all do some form of these steps automatically as part of our normal workflow but it is worth putting some thought into it up front.
Validation
Validate your data, make sure it is complete and intact. You cannot catch all issues while on site but you can catch, and correct, the most significant errors. The easiest steps are:
- Do the files exist? Prior to starting the exercise you should know what you expect to collect each day. Make a checklist for everything and as the data comes in, check it off. If anything is missing, if it doesn’t exist in your collection, go get it. If it is truly missing and cannot be recovered or recreated, log this so an analyst will not spend hours looking for it months later.
- Are the files intact? The easiest check is to open them (read only, or from a read only file system) with an application that should be able to read them. This could be a simple text editor for CSV files or Excel or a database or …. Log the fact that you did this, and the result
- Sanity check. You probably cannot do a detailed validation that all the data is present and sane but you can:
- Check timestamps. Are they from today?
- Check volume of data. Is there enough to cover the expected time frame and data source?
- Check beginning and end of the file. Is anything corrupted or cut off?
You may not be able to immediately correct any issues, but documenting them now will save a lot of effort later.
Example
For an upcoming exercise, you might proceed as follows:
- All files will live in an access controlled Google Drive that is only accessible to the collections team
- The collections team will copy (not move) files to appropriate locations once the data collection process has been validated
- Vendors are required to provide copies of all CUAS system logs prior to departing the site. (This would be part of a daily signout process.)
- For each vendor, and each day, create a thumb drive. This will be used to collect the associated data.
- Create a log to track each thumb drive. Where is it? Who last touched it? Did someone confirm that the vendor populated it with the expected data? Did the team validate the data – intact, complete?
- When the thumb drive comes back
- Copy (not move) the files to a temporary location
- Lock the thumb drive to prevent modifications and store it in a secure location
- Validate the files. If there are any issues, prioritize resolving them now
- Rename as appropriate
- Move (not copy) the files from the temporary location to the master location
- Update the log